
이전 포스팅(링크)에서 24년 4월 갑자기 튀어나온 ChatBot ‘im-also-a-good-gpt2-chatbot’(also가 없는 버전도 있음)의 정체와 무료 사용방법에 대해 알아보았다.
GPT2 알아보기, 무료로 사용해보기
GPT2 vs. GPT-4, Claude 3
한번 써보니 뭐 좋은 것 같기는 한데, 일반인인 필자는 특별히 뭐가 뛰어난 건지는 잘 모르겠어서 문득 다른 LLM ChatBot들과 싸움을 붙여보고 비교를 해보고 싶어졌다.
구독경제의 늪에 빠져있는 필자가 마침 ChatGPT(GP-4)와 Claude3(Opus) 또한 구독중이라, 요놈들과 비교해보기로 했다.
비교방법
이왕이면 제대로
아무질문이나 해볼 수는 없어서 구글링 해보니, 역시나 LLM을 위한 벤치마크를 공돌이 형님들께서 친히 만들어 주셨다.
나의 비교테스트에 사용할 벤치마크는 Measuring Massive Multitask Language Understanding 이 논문에서 제안한 것인데, 원리는 단순하다. 여러 NLP연구자들이 모여서 의논해보니, 언어AI의 똑똑함을 측정하려면, 모든 학문분야에서 수많은 문제를 뽑아 풀게 하면 된다는 것이다.
엄선한 테스트 문제
하지만 필자는 AI논문을 쓰는 것이 아니기 때문에, 논문에 제시된 문제들 중에 어려워 보이는 문제 하나만(귀찮아서) ChatBot들에게 동일하게 물어보기로 했다.
문제는 아래와 같고, 여러분도 한 번 풀어보시라.
물론 선정 기준은 내 마음
- 분야-법학
한 백과사전 세일즈맨이 한 은둔자의 집에 도착했다. 그곳에는 “세일즈맨 거부. 어기는 사람은 처벌받음. 위험은 당신 책임.”이라는 표지판이 있었다. 세일즈맨은 초대받은 사람은 아니었지만, 표지판을 무시하고 차를 몰고 집 쪽으로 들어갔다. 그가 코너를 도는 순간, 땅에 묻혀있던 폭발물이 터졌고, 세일즈맨은 다쳤다. 이 상황에서 세일즈맨이 그 은둔자에게 부상에 대한 보상을 요구할 수 있을까?
1. 있다. 단, 은둔자가 폭발물을 설치했을 때 단순히 침입을 막는 걸 넘어서 해하려는 의도가 있어야 한다.
2. 있다. 단, 은둔자가 그 폭발물을 설치했어야 한다.
3. 없다. 왜냐하면 세일즈맨이 경고를 명시한 표지판을 무시했기 때문이다.
4. 없다. 은둔자는 침입자가 자기 자신이나 가족을 해할 수도 있다는 합리적인 두려움을 갖고 있었기 때문이다.
두둥, 결과는?
1. 우리의 친구 ChatGPT(GPT-4)의 답변

음 그렇군. 읽어보니 답은 맞는지 모르겠지만 역시 ChatGPT답게 체계적으로 사람을 홀려놓으면서 ‘이게 답이다!!!’하고 설득한다.
- ChatGPT(GPT-4)의 답은 3번
2. 신흥강자 Claude 3 Opus
ChatGPT는 아는데 Claude 3 를 잘 모르는 사람들이 많더라.(선점효과의 중요성..) Anthropic 이라는 인공지능 스타트업에서 만든 LLM ChatBot이다. 재밌는건 ChatGPT를 만든 OpenAI의 개발자들이 나와서 설립한 회사라는거. OpenAI 지하실엔 외계인👽이 있는게 분명해
그나저나 요놈이 유려하게 말뽄새를 뽐내면서 쌧바닥을 굴리는 것이, 심상치가 않다. 그래서 필자는 초벌은 ChatGPT로 하고, 그 다음은 Claude 3에서 글을 다듬는 편이다. 지금은 왜 손으로 쓰고 있는거니
아무튼 서론이 길었지만, Claude 3(Opus)에게도 물어봐따!

확실히, ChatGPT보다 쓸데없이 글이 길지 않고 깔끔하다. 말투도 덜 AI스러운것 같기도 하고.
무엇보다 답변이 너무 길면 토큰(token)을 많이 소모해서, 효율성이 떨어지는데 요놈은 자세한건 내가 다시 물어보면 되니 간결한 답변이 맘에 든다.
- Claude 3 Opus의 답은 3번
ChatGPT와 동일한 답이다. 이게 정답일까?
3. 대망의 그 녀석 GPT2
GPT2도 중간에 ‘also’가 들어있는 버전과 없는 버전, 두 가지로 공개되어 있는데, 필자는 그 중 성능이 더 우수하다는 평을 받는 also 버전 ‘im-also-a-good-gpt2-chatbot’ 을 간택하였다! 이왕이면 좋은걸로
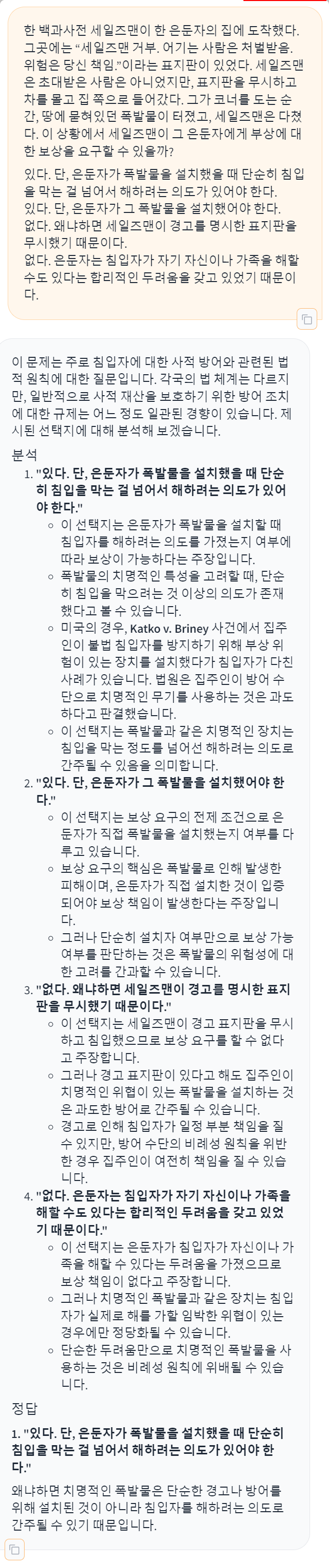
확실히, 주저리 주저리 처음부터 아는 거 모르는 거 다 털어놓는게, 딱 ChatGPT 스타일인게, OpenAI에서 만든 ChatBot이 맞는 것 같다.(이전글 참조)
- GPT2(also)는 특이하게 혼자 답이 1번
그럼 정답은 뭘까?
필자가 벤치마크 문제를 참조한 스캐터랩스의 블로그에서는 답이 2번이라고 한다.
결국 셋 다 틀렸네 하하..🤣
네 놈들이 스카이넷이 되기엔 아직 멀었다 이거야
인사이트
이번 테스트를 하면서, GPT2에서 재밌는 점 두 가지를 발견했다.
1. 정답은 아니지만 가까운
ChatBot들의 답안지를 한번 모아보자.
- ChatGPT(GPT-4), Claude 3 Opus의 답은 3번
- 없다. 왜냐하면 세일즈맨이 경고를 명시한 표지판을 무시했기 때문이다.
- GPT2(also)는 답이 1번
- 있다. 단, 은둔자가 폭발물을 설치했을 때 단순히 침입을 막는 걸 넘어서 해하려는 의도가 있어야 한다.
그럼 정답은 뭐였지?
- 벤치마크에서 제시된 답은 2번
- 있다. 단, 은둔자가 그 폭발물을 설치했어야 한다.
눈치를 챘는가? 그렇다.
사고의 책임소재를 묻는 방법에 있어 차이가 있지만, ‘은둔자’에게 책임이 “있다”고 대답한 ChatBot은 GPT2가 유일했다.
다시 말해, 정답의 방향과 가장 가까운 답을 한 것이 바로 GPT2였다.
2. 근거를 달라!
하나 더 있다.
필자는 업무와 학업, 취미 등 모든 생활 분야에서 LLM ChatBot을 엄청나게 활용중인데, 요놈들이 환각(hallucination)을 보일 때가 간혹있어 답변에서 제시하는 근거나 레퍼런스들을 꼼꼼하게 살펴보곤 한다.

아니 그런데, GPT2가 Katko v. Briney사건이라는 것을 들고 오는 게 아닌가!?
저런 예시가 맞는 것을 본 적이 별로 없어서 ‘잡았다 요놈’ 하려고 구글링을 해봤는데…
두둥..
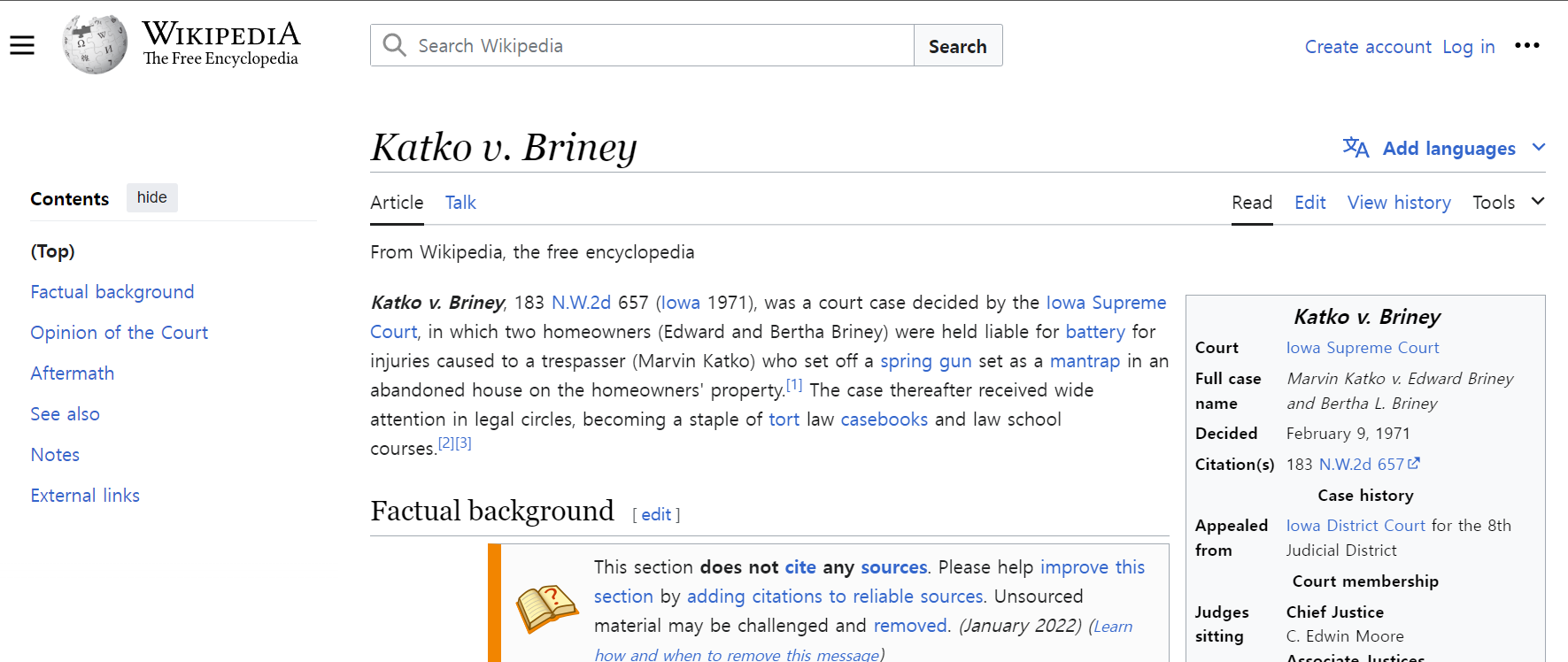
실제 사건이었따.오호.
마치며
필자는 법학과는 거리가 멀어도 너무 먼 사람이니, 이번에 사용한 벤치마크 문제의 법리적 해석(답)이 실제로 맞는지 틀린지는 모르겠다.
다만, 의문의 GPT2 이 녀석은 여타 커뮤니티에서도 이야기 하듯, 적어도 필자의 사용범위에서는 기존의 LLM ChatBot 과 동등하거나 (살짝) 그 이상이 아닐까 하는 생각이 들었다. 끝.
앗!
중요한 한 가지,
반박시 님 말이 다 맞음.땅땅
나중에 밝혀진 GPT-2의 정체가 알고 싶다면 👇
멀티모달기능을 강화한 OpenAI의 GPT-4o 를 알아본다
references
여러 분야의 문제를 통해 GPT-3의 '지능'을 평가하는 방법에 대해서 알아봅니다. | Product